

In this blog post, we will look into installing Spark on Hadoop cluster. Below is a step-by-step guide for the entire installation procedure.
-
Change directory to hadoop installation directory. In my case, I have installed hadoop in /opt/local/hadoop
$cd /opt/local/hadoop -
I have hadoop 3.2.1 is installed. I have downloaded ths spark 2.4.5 version $ wget
https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
Please verify whether the Spark version supported your hadoop installation version or not.
-
Install scala on all the nodes $sudo apt install scala$scala -version
-
Extract spark and rename
$ tar -xvzf spark-2.4.5-bin-hadoop2.7.tgz $ mv spark-2.4.5-bin-hadoop2.7 spark
-
Set Spark_Home in environment variable
$cd $vim ~/.basrc Add following line in bashrc export SPARK_HOME=/opt/local/hadoop/spark export PATH=$PATH:$SPARK_HOME/bin
-
source ~/.bashrc
-
cd $SPARK_HOME/conf
-
Configuring spark-env.sh filemv spark-env.sh.template spark-env.sh
Edit spark-env.sh and add below line
export SPARK_MASTER_HOST=server1.bigdata.com export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 -
Configuring spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.confEdit and add below lines in spark-defaults.confspark.master yarn spark.yarn.am.memory 768m
spark.driver.memory 512m
spark.executor.memory 512m
spark.eventLog.enabled true
spark.eventLog.dir hdfs://server1.bigdata.com:9000/sparklogs
spark.executor.memory 512m
spark.eventLog.enabled true
spark.eventLog.dir hdfs://server1.bigdata.com:9000/sparklogs
Below is the explanation for each of the variable configured in the spark-defaults.conf
-
“Spark.master yarn”
This will set spark ready to interact with yarn -
“spark.yarn.am.memory 768m”
This will set maximum memory allocation allowed to the yarn container. In this case we have set it to 768 megabytes. If the memory requested will be more than the maximum, yarn will reject the creation of the container and spark application will fail to start.
The value of yarn memory memory application must be lower than that of yarn.scheduler.maximum-allocation-mb in $HADOOP_CONF_DIR/yarn-site.xml.
c. “Spark.driver.memory 512m”
Set 512 megabytes default memory allocated to Spark Driver in cluster mode In cluster mode, the Spark driver runs inside YARN Application master. The amount of memory requested by spark at initialization is configured.
Set 512 megabytes default memory allocated to Spark Driver in cluster mode In cluster mode, the Spark driver runs inside YARN Application master. The amount of memory requested by spark at initialization is configured.
d. “spark.executor.memory 512m”
Set the Spark Executor base memory to 512 megabytes
The Spak Executors allocation is calculated based on two parameter inside $SPARK_HOME/conf/spark-defaults.conf
Set the Spark Executor base memory to 512 megabytes
The Spak Executors allocation is calculated based on two parameter inside $SPARK_HOME/conf/spark-defaults.conf
-
? spark.executor.memory: sets the base memory used in the calculation
-
? spark.yarn.executor.memoryOverhead: is added to the base memory,It defaults to 7% of base memory, with a minimum of 384 MBExample: for spark.executor.memory of 1Gb , the required memory is 1024+384=1408MB. For 512MB, the required memory will be 512+384=896MB
???????
e. To enable Spark job logs in hdfs add in spark-defaults.conf spark.eventLog.enabled true
spark.eventLog.dir hdfs://server1.bigdata.com:9000/sparklogs
spark.eventLog.dir hdfs://server1.bigdata.com:9000/sparklogs
Make sure to create “sparklogs” directory in the hdfs. $hdfs dfs -mkdir /sparklogs
10.Configuring salves
mv slaves.template slaves
Edit and below line slaves file
server1.bigdata.com server2.bigdata.com server3.bigdata.com
11. Copy the spark directory on slaves node.
Create spark directory in hadoop home directory on both the slave nodes server1.bigdata.com and server2.bigdata.com from hadoopuser
Create spark directory in hadoop home directory on both the slave nodes server1.bigdata.com and server2.bigdata.com from hadoopuser
Below command on master node will copy the spark configuration and other detail on slave nodes:
$scp -r /opt/local/hadoop/spark/* h?adoopuser@server2.bigdata.com?:/opt/local/hadoop
$scp -r /opt/local/hadoop/spakr/* hadoopuser@server3.bigdata.com?:/opt/local/hadoop
Congratulations! You have installed Spark on Apache Hadoop cluster. Change the directory to SPARK_HOME
$cd $SPARK_HOME
$cd $SPARK_HOME
Run below command
$./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --deploy-mode client --driver-memory 1024m --executor-memory 512m --executor-cores 1 examples/jars/spark-examples_2.11-2.4.5.jar
400
$./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --deploy-mode client --driver-memory 1024m --executor-memory 512m --executor-cores 1 examples/jars/spark-examples_2.11-2.4.5.jar
400
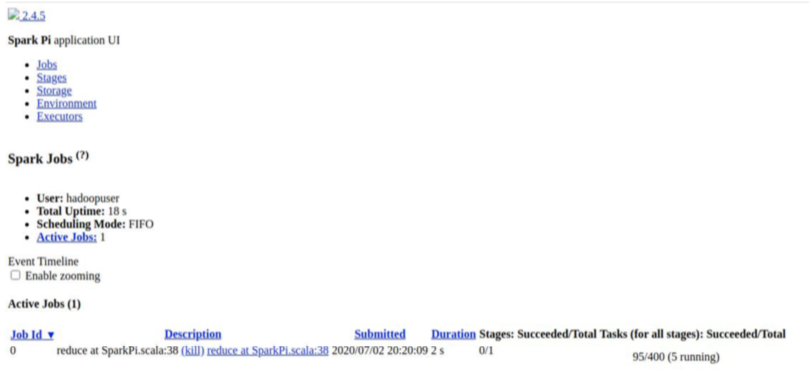
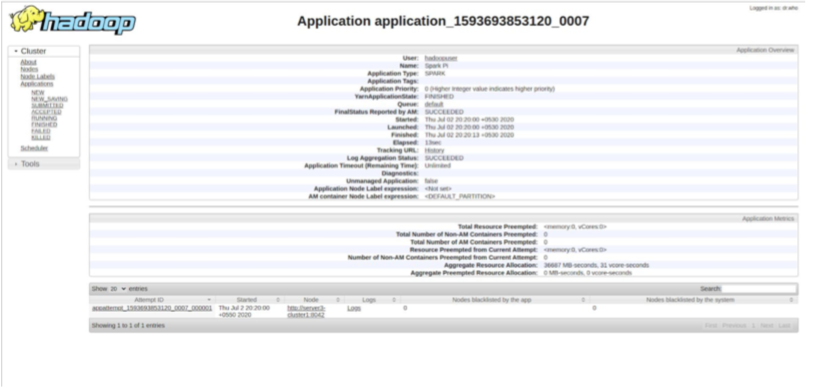
During the job execution you can check the status on spark web UI
http://server1.bigdata.com:4040/jobs/
We are a SaaS Application Development Company that provides end-to-end web and mobile app development services with a focus on next-gen technologies. Our development team is skilled at using the latest tools, frameworks, and SDKs to build performance-driven web and mobile applications that are easy to scale and customize. We have successfully completed several full-fledged SaaS projects for clients from across the globe. Our 360-degree SaaS application development services include quality assurance and software testing services.
#SaaSApplicationDevelopment #mobileappdevelopment
No comments:
Post a Comment