What is Android Wi-Fi P2p APIs?
It allows nearby devices to connect and communicate among themselves without needing to connect to a network or hotspot.
Advantages over traditional Wi-Fi ad-hoc networking?
- Wifi-Direct supports WPA2(Wifi Protected Access) encryption.
- Android doesn't support Wi-Fi ad-hoc mode.
Let's implement :
Set up application permissions :

Set up a broadcast receiver :
With the help of broadcast receiver we will be able to listen various phases of connections between 2 devices.
Constructor of broadcast receiver class :

The onReceive() method of broadcast will look like this :

Create an activity and register broadcast receiver :
1- Create intent Filter :
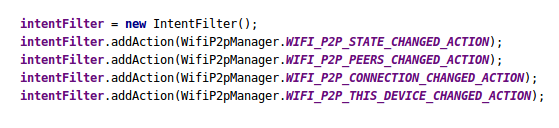
WifiP2pManager.WIFI_P2P_STATE_CHANGED_ACTION : Indicates a change in the Wi-Fi P2P status.
WifiP2pManager.WIFI_P2P_PEERS_CHANGED_ACTION : Indicates a change in the list of available peers.
WifiP2pManager.WIFI_P2P_CONNECTION_CHANGED_ACTION : Indicates the state of Wi-Fi P2P connectivity has changed.
WifiP2pManager.WIFI_P2P_THIS_DEVICE_CHANGED_ACTION : Indicates this device's details have changed.
2- Register receiver in OnCreate :

Listen to broadcast receiver :
1- Now when you run the application you will find that your control will get to the WIFI_P2P_STATE_CHANGED_ACTION, so this the point where you will start finding the peers(nearby you) if your WIFI state is enabled.
So in your broadcast receiver check the wifi-state and start listen for peers if it is enabled.

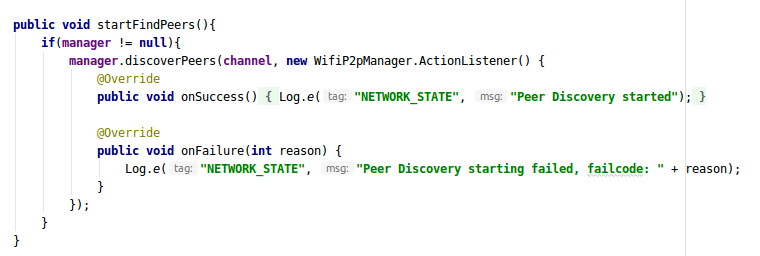
And your startFindPeers method will look like this on Activity :
2- As soon as you successfully discover the nearby peers the WIFI_P2P_PEERS_CHANGED_ACTION in your broadcast receiver class gets trigerred, so this is the point to get the list of all the available devices.
So, inside your broadcast onReceive method and add the following code in WIFI_P2P_PEERS_CHANGED_ACTION and register your peer callback :

This requestPeer() method is implicitly provided by WifiP2pManager class but this peerListListener is custom and is used to as a callback for peerList :
PeerListener will be like this :

3- Now if the call is successful then you will get the list of all available devices with various other parameters in onPeersAvailable, iterate through the list and select one device to connect.
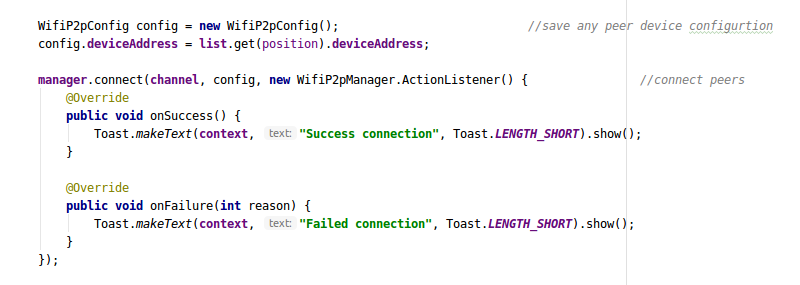
Now next step is to get the peer configurations of the selected item in the peerList and connect with peers using deviceAddress :
4- Once we get the successfull connection with the peer the WIFI_P2P_CONNECTION_CHANGED_ACTION is trigerred and this is the point to get the connection info from the connectionListener callback.
The connection info can be get by passing connection callback as a parameter in requestConnectionInfo() method.
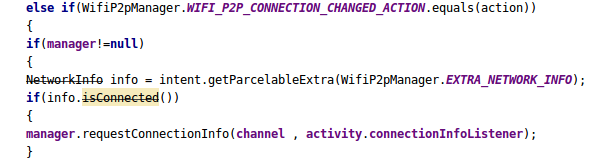
And the connectionInfoListener will look like this :
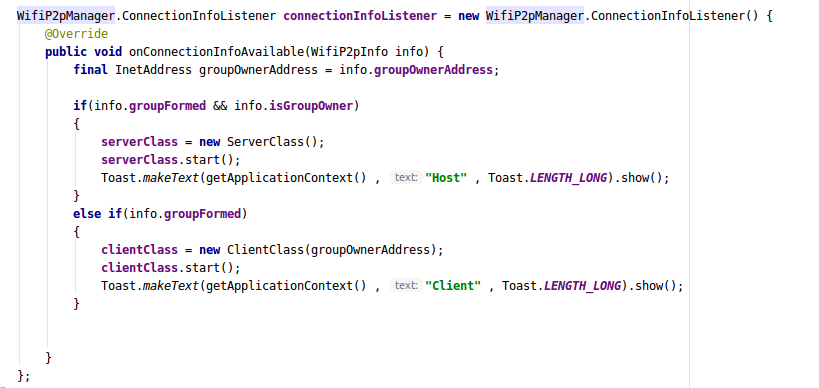
Great our peers are now connected to each other and can transfer data between themselves.
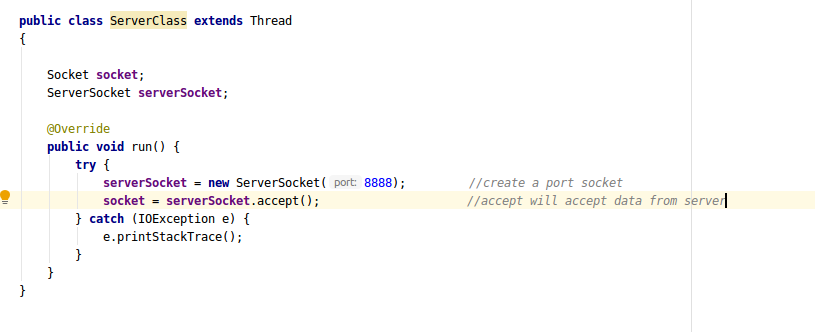
5- To transfer the data you have to create a client and server class based on available connection info.
Let's take a look at server class :
This is the client class :

So finally, the sockets are now connected to each other and data transfer can be done easily using input and output streams of the socket.
We are a seasoned SaaS app development company that provides full-scale software solutions using next-gen technologies. Our team of developers is experienced in using the latest tools and SDKs to build performance-driven and user-friendly software solutions for multiple platforms. We also specialize in providing end-to-end DevOps solutions and cloud app development services for varied business requirements. For technical assistance, contact us at info@oodlestechnologies.com and share your requirements.



